How to build a custom GPT-enabled full-stack app for real-time data
Looking to make ChatGPT answer unfamiliar topics like finding real-time discounts from various online markets? Here's a step-by-step on how to achieve

𝐖𝐡𝐨 𝐈 𝐚𝐦
Bobur is a developer advocate and speaker specializing in software and data engineering. With over 10- years of experience in IT, he blogs about open-source technologies and the community around them.
𝐖𝐡𝐚𝐭 𝐈 𝐝𝐨
I work with companies at different scales to build awareness, drive adoption, and engage with the community for your developer-targeted products. I also create inspiring content, design, and code use cases, projects, and demo apps to boost learning your product.
OpenAI’s GPT has emerged as the foremost AI tool globally and is proficient at addressing queries based on its training data. However, it can not answer questions about unknown topics such as recent events after September 2021, your non-public documents, or information from past conversations. This task gets even more complicated when you deal with real-time data that frequently changes. Moreover, you cannot feed extensive content to GPT, nor can it retain your data over extended periods.
In this case, you need to build a custom LLM (Language Learning Model) app efficiently to give context to the answer process. A promising approach you find on the internet is utilizing LLMs with vector databases that come with costs like increased prep work, infrastructure, and complexity. Keeping source and vectors in sync is painful. Instead, you can use an open-source LLM App library in Python to implement real-time in-memory data indexing directly reading data from any compatible storage and showing this data on Streamlit UI.
This piece will walk you through the steps to develop real-time deal trackers utilizing these tools. The source code is on GitHub.
Learning objectives
You will learn the following throughout the article:
The reason why you need to add custom data to ChatGPT.
How to use embeddings, prompt engineering, and ChatGPT for better question answering.
Build your own ChatGPT with custom data using the LLM App.
Create a ChatGPT Python API for finding real-time discount prices.
Sample app objective
Inspired by this article around enterprise search, our sample app should expose an HTTP REST API endpoint in Python to answer user queries about current sales by retrieving the latest deals from various sources (CSV, Jsonlines, API, message brokers, or databases), filters and presents deals based on user queries or chosen data sources, leverages OpenAI API Embeddings and Chat Completion endpoints to generate AI assistant responses and offers user-friendly UI with Streamlit.
Currently, the project supports two types of data sources and it is possible to extend sources by adding custom input connectors:
Jsonlines - The Data source expects to have a
docobject for each line. Make sure that you convert your input data first to Jsonlines. See a sample data in discounts.jsonlRainforest Product API - gives us all available daily discount data from Amazon products.
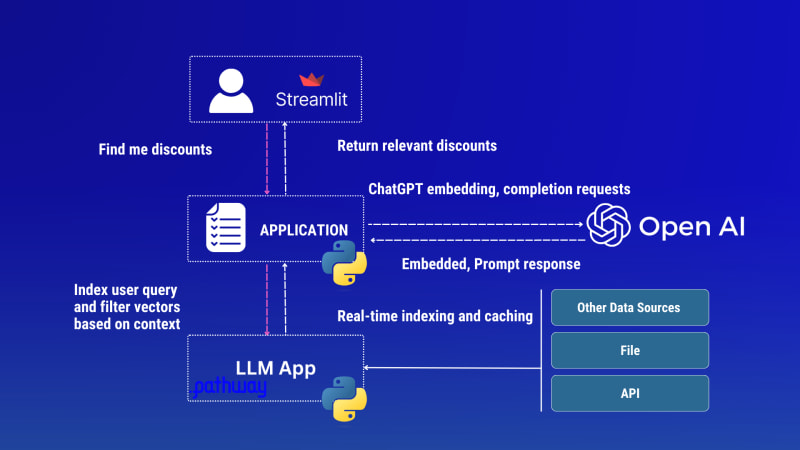
Discounts tracker LLM App architectural diagram
After we give this knowledge to GPT using Streamlit UI (applying a data source), look how it replies:

The app takes both Rainforest API and discounts.csv file documents into account (merges data from these sources instantly.), indexes them in real-time, and uses this data when processing queries.
Why provide ChatGPT with a custom knowledge base?
Before jumping into the ways to enhance ChatGPT, let’s first explore the manual methods of doing so and identify their challenges. Typically, ChatGPT is expanded through prompt engineering. Assume that you want to find real-time discounts/deals/coupons from various online markets.
For example, when you ask ChatGPT “Can you find me discounts this week for Adidas men’s shoes?”, a standard response you can get from the ChatGPT UI interface without having custom knowledge is:

As evident, GPT offers general advice on locating discounts but lacks specificity regarding where or what type of discounts, among other details. Now to help the model, we supplement it with discount information from a trustworthy data source. You must engage with ChatGPT by adding the initial document content prior to posting the actual questions. We will collect this sample data from the Amazon products deal dataset and insert only a single JSON item we have into the prompt:

As you can see, you get the expected output and this is quite simple to achieve since ChatGPT is context-aware now. However, the issue with this method is that the model’s context is restricted (gpt-4 maximum text length is 8,192 tokens). This strategy will quickly become problematic when input data is huge you may expect thousands of items discovered in sales and you can not provide this large amount of data as an input message. Also, once you have collected your data, you may want to clean, format, and preprocess data to ensure data quality and relevancy. If you utilize the OpenAI Chat Completion endpoint or build custom plugins for ChatGPT, it introduces other problems as follows:
Cost — By providing more detailed information and examples, the model’s performance might improve, though at a higher cost (For GPT-4 with an input of 10k tokens and an output of 200 tokens, the cost is $0.624 per prediction). Repeatedly sending identical requests can escalate costs unless a local cache system is utilized.
Latency — A challenge with utilizing ChatGPT APIs for production, like those from OpenAI, is their unpredictability. There is no guarantee regarding the provision of consistent service.
Security — When integrating custom plugins, every API endpoint must be specified in the OpenAPI spec for functionality. This means you’re revealing your internal API setup to ChatGPT, a risk many enterprises are skeptical of.
Offline Evaluation — Conducting offline tests on code and data output or replicating the data flow locally is challenging for developers. This is because each request to the system may yield varying responses.
Tutorial
You can follow the steps below to understand how to build a discount finder app. The project source code can be found on GitHub. If you want to quickly start using the app, you can skip this part clone the repository, and run the code sample by following the instructions in the README.md file there. The tutorial consists of two parts:
Developing and exposing AI-powered HTTP REST API using Pathway and LLM App.
Designing UI with Streamlit to consume the API data through REST.
Part 1: Develop API
To add custom data for ChatGPT, first, you need to follow the steps to build a data pipeline to ingest, process, and expose data in real-time with the LLM App.
Step 1. Data collection (custom data ingestion)
For simplicity, we can use any Jsonlines as a data source. The app takes Jsonlines files like discounts.jsonl and uses this data when processing user queries. The data source expects to have an doc object for each line. Make sure that you convert your input data first to Jsonlines. Here is an example of a Jsonline file with a single raw:
{"doc": "{'position': 1, 'link': 'https://www.amazon.com/deal/6123cc9f', 'asin': 'B00QVKOT0U', 'is_lightning_deal': False, 'deal_type': 'DEAL_OF_THE_DAY', 'is_prime_exclusive': False, 'starts_at': '2023-08-15T00:00:01.665Z', 'ends_at': '2023-08-17T14:55:01.665Z', 'type': 'multi_item', 'title': 'Deal on Crocs, DUNLOP REFINED(\u30c0\u30f3\u30ed\u30c3\u30d7\u30ea\u30d5\u30a1\u30a4\u30f3\u30c9)', 'image': 'https://m.media-amazon.com/images/I/41yFkNSlMcL.jpg', 'deal_price_lower': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48'}, 'deal_price_upper': {'value': 52.14, 'currency': 'USD', 'symbol': '$', 'raw': '52.14'}, 'deal_price': 35.48, 'list_price_lower': {'value': 49.99, 'currency': 'USD', 'symbol': '$', 'raw': '49.99'}, 'list_price_upper': {'value': 59.99, 'currency': 'USD', 'symbol': '$', 'raw': '59.99'}, 'list_price': {'value': 49.99, 'currency': 'USD', 'symbol': '$', 'raw': '49.99 - 59.99', 'name': 'List Price'}, 'current_price_lower': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48'}, 'current_price_upper': {'value': 52.14, 'currency': 'USD', 'symbol': '$', 'raw': '52.14'}, 'current_price': {'value': 35.48, 'currency': 'USD', 'symbol': '$', 'raw': '35.48 - 52.14', 'name': 'Current Price'}, 'merchant_name': 'Amazon Japan', 'free_shipping': False, 'is_prime': False, 'is_map': False, 'deal_id': '6123cc9f', 'seller_id': 'A3GZEOQINOCL0Y', 'description': 'Deal on Crocs, DUNLOP REFINED(\u30c0\u30f3\u30ed\u30c3\u30d7\u30ea\u30d5\u30a1\u30a4\u30f3\u30c9)', 'rating': 4.72, 'ratings_total': 6766, 'page': 1, 'old_price': 49.99, 'currency': 'USD'}"}
The cool part is, that the app is always aware of changes in the data folder. If you add another JSONlines file, the LLM app does magic and automatically updates the AI model’s response.
Step 2: Data loading and mapping
With Pathway’s JSONlines input connector, we will read the local JSONlines file, map data entries into a schema and create a Pathway Table. See the full source code in app.py:
...
sales_data = pw.io.jsonlines.read(
"./examples/data",
schema=DataInputSchema,
mode="streaming"
)
Map each data row into a structured document schema. See the full source code in app.py:
class DataInputSchema(pw.Schema):
doc: str
Step 3: Data embedding
Each document is embedded with the OpenAI API and retrieves the embedded result. See the full source code in embedder.py:
...
embedded_data = embeddings(context=sales_data, data_to_embed=sales_data.doc)
Step 4: Data indexing
Then we construct an instant index on the generated embeddings:
index = index_embeddings(embedded_data)
Step 5: User query processing and indexing
We create a REST endpoint, take a user query from the API request payload, and embed the user query with the OpenAI API.
...
query, response_writer = pw.io.http.rest_connector(
host=host,
port=port,
schema=QueryInputSchema,
autocommit_duration_ms=50,
)
embedded_query = embeddings(context=query, data_to_embed=pw.this.query)
Step 6: Similarity search and prompt engineering
We perform a similarity search by using the index to identify the most relevant matches for the query embedding. Then we build a prompt that merges the user’s query with the fetched relevant data results and send the message to the ChatGPT Completion endpoint to produce a proper and detailed response.
responses = prompt(index, embedded_query, pw.this.query)
We followed the same in-context learning approach when we crafted the prompt and added internal knowledge to ChatGPT in the prompt.py.
prompt = f"Given the following discounts data: \\n {docs_str} \\nanswer this query: {query}"
Step 7: Return the response
The final step is just to return the API response to the user
# Build prompt using indexed data
responses = prompt(index, embedded_query, pw.this.query)
Step 9: Put everything together
Now if we put all the above steps together, you have LLM-enabled Python API for custom discount data ready to use as you see the implementation in the app.py Python script.
import pathway as pw
from common.embedder import embeddings, index_embeddings
from common.prompt import prompt
def run(host, port):
# Given a user question as a query from your API
query, response_writer = pw.io.http.rest_connector(
host=host,
port=port,
schema=QueryInputSchema,
autocommit_duration_ms=50,
)
# Real-time data coming from external data sources such as jsonlines file
sales_data = pw.io.jsonlines.read(
"./examples/data",
schema=DataInputSchema,
mode="streaming"
)
# Compute embeddings for each document using the OpenAI Embeddings API
embedded_data = embeddings(context=sales_data, data_to_embed=sales_data.doc)
# Construct an index on the generated embeddings in real-time
index = index_embeddings(embedded_data)
# Generate embeddings for the query from the OpenAI Embeddings API
embedded_query = embeddings(context=query, data_to_embed=pw.this.query)
# Build prompt using indexed data
responses = prompt(index, embedded_query, pw.this.query)
# Feed the prompt to ChatGPT and obtain the generated answer.
response_writer(responses)
# Run the pipeline
pw.run()
class DataInputSchema(pw.Schema):
doc: str
class QueryInputSchema(pw.Schema):
query: str
Part 2: Add an interactive UI
To make your app more interactive and user-friendly, you can use Streamlit to build a front-end app. See the implementation in this app.py file. As you can see in the Streamlit implementation extracted code below, it handles Discounts API requests (We exposed in Part 1) if a data source is selected and a question is provided:
if data_sources and question:
if not os.path.exists(csv_path) and not os.path.exists(rainforest_path):
st.error("Failed to process discounts file")
url = f'http://{api_host}:{api_port}/'
data = {"query": question}
response = requests.post(url, json=data)
if response.status_code == 200:
st.write("### Answer")
st.write(response.json())
else:
st.error(f"Failed to send data to Discounts API. Status code: {response.status_code}")
Running the app
Follow the instructions in the README.md file’s How to run the project section to run the app. Note that you need to run API and UI separately as two different processes. Streamlit connects to the Discounts backend API automatically and you will see the UI frontend is running on your browser.

Streaming UI for discounts tracker.
Technically, there are other ways to integrate Pathway’s LLM App with Streamlit:
You can run Pathway’s LLM App as a subprocess communicating with the subprocess over inter-process communications (sockets or TCP/IP, maybe with random ports, maybe with signals to e.g. trigger a state dump that can be picked up/pickled).
It is also possible to run the app with a single
docker compose upcommand. See the run with the Docker section in the README.md file.
Wrapping up
We’ve only discovered a few capabilities of the LLM App by adding domain-specific knowledge like discounts to ChatGPT. There are more things you can achieve:
Incorporate additional data from external APIs, along with various files (such as Jsonlines, PDF, Doc, HTML, or Text format), databases like PostgreSQL or MySQL, and stream data from platforms like Kafka, Redpanda, or Debedizum.
Improve Streamlit UI to accept any deals API besides Rainforest API.
Maintain a data snapshot to observe variations in sales prices over time, as Pathway provides a built-in feature to compute differences between two alterations.
Beyond making data accessible via API, the LLM App allows you to relay processed data to other downstream connectors, such as BI and analytics tools. For instance, set it up to receive alerts upon detecting price shifts.
If you have any questions, please post them in the comments below or contact me on LinkedIn and Twitter. Join the Discord channel to see how the AI ChatBot assistant works using the LLM App.
About the author
Visit my blog: www.iambobur.com




