Multi-Stream Joins With SQL

𝐖𝐡𝐨 𝐈 𝐚𝐦
Bobur is a developer advocate and speaker specializing in software and data engineering. With over 10- years of experience in IT, he blogs about open-source technologies and the community around them.
𝐖𝐡𝐚𝐭 𝐈 𝐝𝐨
I work with companies at different scales to build awareness, drive adoption, and engage with the community for your developer-targeted products. I also create inspiring content, design, and code use cases, projects, and demo apps to boost learning your product.
Real-time data is becoming increasingly important in today's fast-paced business world, as companies seek to gain valuable insights and make informed decisions based on the most up-to-date information available. However, processing and analyzing real-time data can be a challenge, particularly when it comes to joining multiple streams of data together in real-time. In this article, we'll explore the concept of multi-stream joins in SQL, and discuss some tips and techniques for performing these joins effectively using a streaming database.
Multi-stream Joins: What Are They?
A multi-stream join involves combining two or more streams of data together in real-time to create a single output stream that reflects the current state of the data. This can be a powerful technique for analyzing real-time data from multiple sources, such as IoT devices, social media feeds, e-commerce apps, or financial markets.
In SQL, joins are typically performed using a query that specifies the input streams, the join conditions, and any additional filtering or aggregation functions that are required. The exact syntax for these queries can vary depending on the database system being used, but the basic principles are the same.
Imagine you work for a ride-sharing company like Uber that operates in multiple cities. You have a stream of data from your drivers' GPS devices that includes their location, speed, and other relevant information. You also have a stream of data from your customers' mobile apps that includes their location, destination, and other relevant details.
To improve the overall customer experience and optimize driver efficiency, you want to join these two data streams together in real-time to gain a better understanding of where your drivers are located, which customers are waiting for rides, and which routes are most efficient. See below a couple of scenarios.
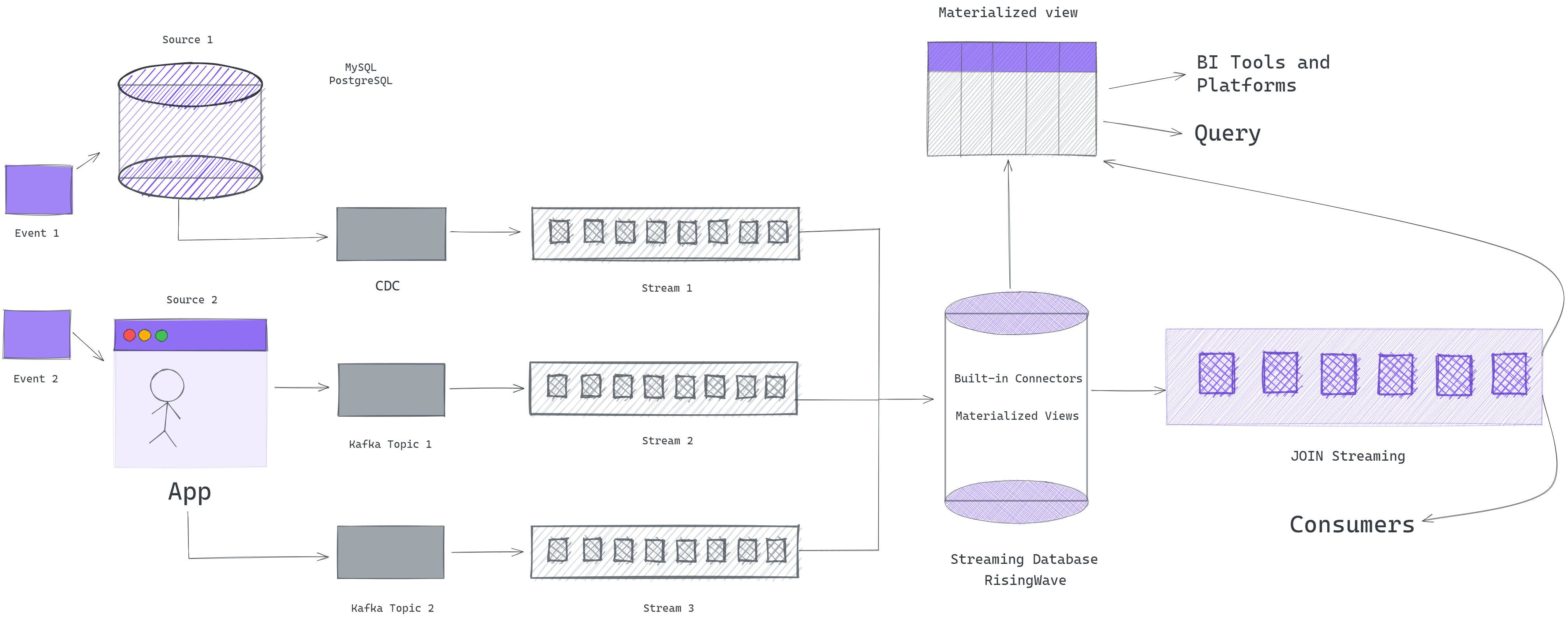
Streaming database for multi-stream joins
If you're looking to perform stream-to-stream joins in SQL, a streaming database helps you get the most out of your data. By using the streaming database, you can run SQL queries continuously on single streams, and join two or more streams. Much like other popular RDBMS (relational database management system), a streaming database can join together any two datasets/tables expressions using various sources or materialized views) into a single table expression. The main difference between joins with streaming databases and traditional databases is the nature of the data being processed. In a traditional database, data is typically stored in tables, and queries are run on this stored data at a point in time. On the other hand, in a streaming database, data is processed in real-time as it is being generated, and queries are run on this real-time data stream as data arrives in the form of topics from different message brokers like Kafka. You can read more about how a streaming database differs from a traditional database?.
In the next section, I used RisingWave as a streaming database and provided some examples of how you could use SQL to perform a multi-stream join. You can find out more about how to choose the right streaming database.
RisingWave uses Postgres-compatible SQL as the interface to manage and query data. This guide will walk you through some of the most used SQL commands in RisingWave.
Join streams with RisingWave
Imagine you want to analyze your ride-sharing data and you might choose to join the driver data stream and the customer data stream based on the location field, as this would allow you to track which drivers are closest to which customers and ensure that you're dispatching drivers efficiently.
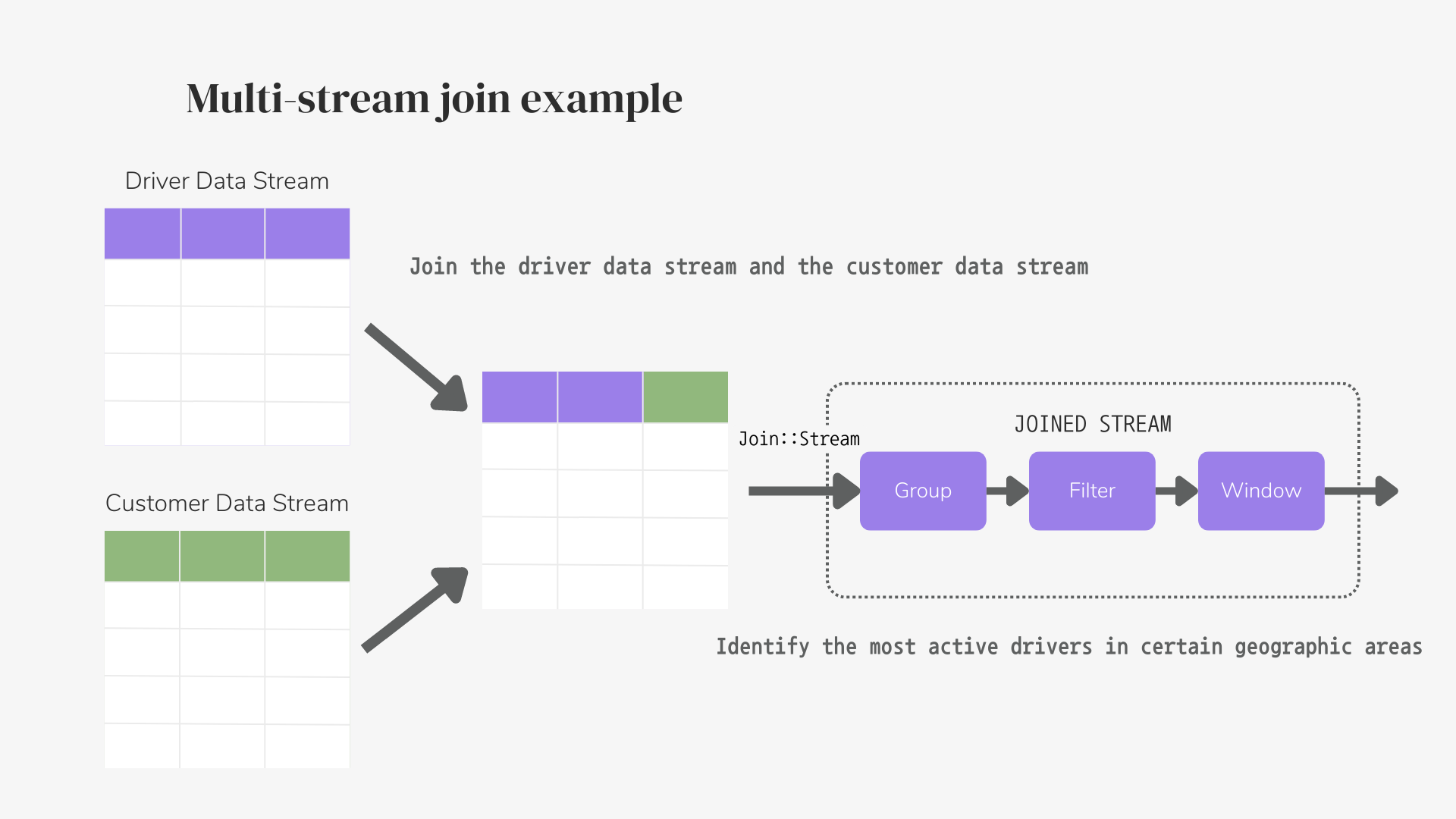
The sample data below demonstrate the typical data stream generated by the ride-sharing app:
Driver Data Stream
| driver_id | location | speed | rating | event_timestamp |
| 101 | San Francisco | 60 | 4 | 2023-04-01 10:30:00 |
| 102 | New York | 50 | 5 | 2023-04-01 10:33:00 |
| 103 | Los Angeles | 45 | 1 | 2023-04-01 10:31:00 |
| ... | ... | ... | ... | ... |
Customer Data Stream
| customer_id | pickup_location | destination | event_timestamp |
| 201 | San Francisco | Palo Alto | 2023-04-01 10:30:00 |
| 202 | New York | Brooklyn | 2023-04-01 10:33:00 |
| 203 | Los Angeles | Santa Monica | 2023-04-01 10:31:00 |
| ... | ... | ... | ... |
Creating a source for a streaming source
The first thing you do is to connect the streaming database to a streaming source. A source is a resource that RisingWave can read data from. The streaming source can be two tables in your relational database (MySQL, PostgreSQL, or another) and you can ingest data using Change Data Capture (CDC) and RisingWave built-in connector. Or the source can be a Kafka broker. You can create a source in RisingWave using the CREATE SOURCE command. For example, the mapping for the drivers Kafka topic to RisingWave source might look like this:
CREATE SOURCE driver_data (
driver_id BIGINT,
location VARCHAR,
speed BIGINT,
) WITH (
connector = 'kafka',
topic = 'driver_topic',
properties.bootstrap.server = 'message_queue:29092',
scan.startup.mode = 'earliest'
) ROW FORMAT JSON;
And you will have a second source for customer_topic too.
Continuous queries on a stream
Afterward, you can query streams with SQL like you would query them in the ordinary relational database but in the streaming database, the data is shown in real time as new data is added to the source. This simple equijoin query would select all fields from both data streams and join them based on the location field.
SELECT driver_data.*, customer_data.*
FROM driver_data
JOIN customer_data
ON driver_data.location = customer_data.pickup_location
You might want to persist all rides-related data in the streaming database. You can create a new table rides in the database that contains information about each ride, including the driver ID, the customer ID, the pickup location, the drop-off location, and the fare amount. In this case, you want to join the incoming continuous drivers data streams with the rides table based on the driver ID. The below join query will allow you to combine information about each driver's location and rating with information about the rides they have completed to identify the most active drivers in certain geographic areas.
SELECT driver_data.driver_id, driver_data.location, driver_data.rating, COUNT(ride_data.ride_id) as total_rides
FROM driver_data
JOIN ride_data
ON driver_data.driver_id = ride_data.driver_id
WHERE driver_data.location = 'San Francisco'
GROUP BY driver_data.driver_id, driver_data.location, driver_data.rating
ORDER BY total_rides DESC
Result:
| driver_id | location | rating | total_rides |
| 101 | San Francisco | 4 | 2 |
| ... | ... | ... | ... |
Window joins in RisingWave
Sometimes you are interested in the events during any time intervals. A window join is a type of join operation that is commonly used in streaming databases that allows you to join two streams of data based on a time window. RisingWave offers two types of windows:
For example, you may want to calculate the average speed of drivers within a certain distance from a customer's pickup location, over a rolling window of the past 10 minutes. In this case, your SQL query might look something like this:
SELECT customer_data.*, AVG(driver_data.speed) AS avg_speed
FROM customer_data
JOIN driver_data
ON ST_DISTANCE(driver_data.location, customer_data.pickup_location) < 5
GROUP BY TUMBLE(customer_data.event_time, INTERVAL '10' MINUTE), customer_data.customer_id
Result:
| customer_id | pickup_location | destination | event_time | avg_speed |
| 201 | San Francisco | Palo Alto | 2023-04-01 10:30:00 | 60.0 |
| 203 | Los Angeles | Santa Monica | 2023-04-01 10:31:00 | 45.0 |
| 202 | New York | Brooklyn | 2023-04-01 10:33:00 | 50.0 |
This query would select all fields from the customer data stream and calculate the average speed of drivers within 5 km of the customer's pickup location. In this query, the TUMBLE() function is used to group the data into tumbling time windows of 10 minutes. The GROUP BY clause aggregates the data within each time window and for each customer separately.
Write merged streams to a materialized view
With the RisingWave streaming database, you can also create materialized views for joined streams. A materialized view is a precomputed snapshot of data that is stored as a table in the streaming database. Materialized views can be particularly useful because they allow you to combine and aggregate data from multiple streams into a single table and the streaming database computes the query results on the fly and updates the virtual table as new data arrives. This can simplify complex queries, improve overall system performance, and responsiveness and provide a more comprehensive view of the data that's easier to work with.
In RisingWave, you need to use the CREATE MATERIALIZED VIEW statement to create a materialized source. Here's an example of a materialized view that can be created by merging the Driver and Rider streams in the ride-sharing data example above.
CREATE MATERIALIZED VIEW most_active_drivers AS
SELECT drivers.driver_id, drivers.location, drivers.rating, COUNT(rides.ride_id) as total_rides
FROM drivers
JOIN rides
ON drivers.driver_id = rides.driver_id
WHERE drivers.location = 'San Francisco'
GROUP BY drivers.driver_id, drivers.location, drivers.rating
ORDER BY total_rides DESC
The materialized view result:
| driver_id | location | rating | total_rides |
| 101 | San Francisco | 4 | 2 |
| 104 | San Francisco | 3 | 1 |
Takeaways
- With a streaming database, you can join two or multiple streams by ingesting them from different data sources.
- You can join tables by table reference, type, and table functions like JOIN.
- It is also possible to join multiple streams based on a time window using the window joins functions like Tumble or Hop.
- The resulting stream would contain the combined data from all streams which means this operation performs expensive calculations. In this case, you can create a materialized view to speed up query performance.
Related resources
- Shared Indexes and Joins in Streaming Databases
- How Change Data Capture (CDC) Works with Streaming Database.
- Query Real-Time Data in Kafka Using SQL.
Recommended content
Community
🙋 Join the Risingwave Community
About the author
Visit my personal blog: www.iambobur.com




